Agent Knowledge Insertion
Agents can digest pdf files / text files / websites as their knowledge source.
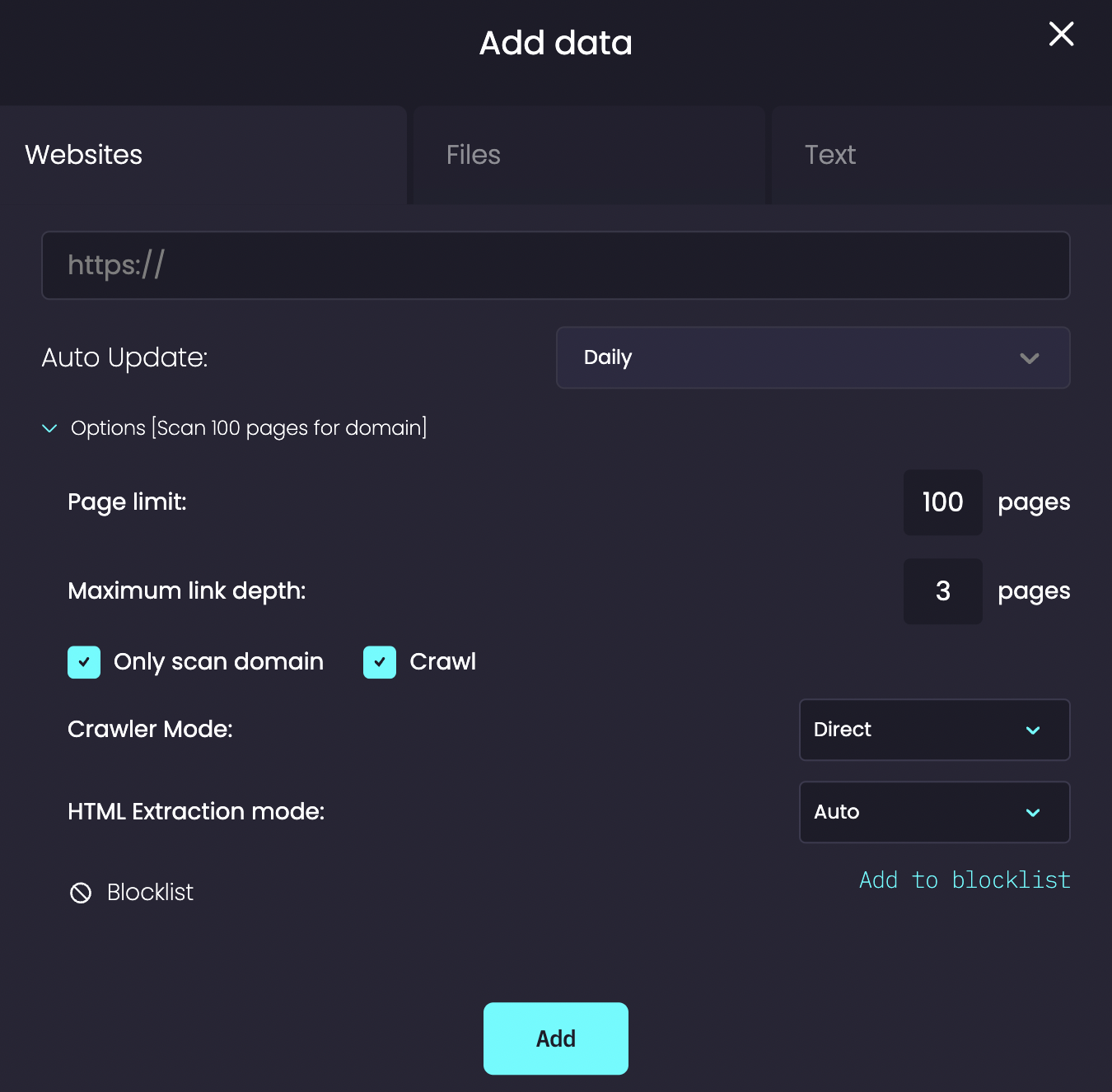
Agents possess the capability to process and comprehend information sourced from PDFs, text files, and websites, thereby enriching their knowledge repository. Once a document is successfully uploaded to an agent, it becomes adept at furnishing answers to queries based on the content encapsulated within that document.
To augment the utility of the agent, it's pivotal to grasp several crucial configuration parameters. These parameters dictate the behavior of the agent when assimilating knowledge from websites:
Scraping a page: This involves extracting textual content from a specified URL and integrating it into the agent's knowledge base. Notably, text embedded within images, rather than being selectable text, cannot be scraped.
Crawling a page: This process entails the comprehensive collection of all links present on a given page.
Page limit: Specifies the total number of pages slated for scraping.
Maximum link depth: Determines the extent of the crawl; starting from the initial page as depth 1, subsequent links are considered at increasing depths.
Only Crawl Domain: Restricts the crawl to links residing within the same domain as the initial URL.
Crawl: Decides whether the page should be crawled. If unselected, the agent will solely scrape the page.
Crawl Mode: Selects the method for extracting page content, with options including direct, proxy, or render.
HTML Extraction Mode: Determines the approach for extracting text content from HTML.
Blocklist: This feature enables the exclusion of pages matching specified patterns. Users can utilize either wildcard or regex expressions for this purpose.
Understanding and configuring these parameters correctly can significantly enhance the efficacy of the content extraction process.
Let's delve into a few scenarios:
Scenario 1:
Objective: Add a single page, such as a Wikipedia article, to the agent's knowledge without crawling.
Actions:
- Add the specific article URL directly to the agent's knowledge.
- Ensure the crawl option remains unchecked.
Scenario 2:
Objective: Include a specific article and all referenced links mentioned within it, even if they are from different domains.
Actions:
- Add the specific article URL to the agent's knowledge.
- Check the crawl option and set the maximum link depth to 2.
- Ensure the "Only scan domain" option remains unchecked.
Scenario 3:
Objective: Exclude pages from the /blog section on the website from scraping.
Actions:
- Add the wildcard expression
https://www.mywebsite.com/blog/*to the blocklist.
Alternatively, utilize the regex expression^https://www\.mywebsite\.com/blog/.*in the blocklist.
Scenario 4:
Objective: Scrape all website pages except those from the /blog section.
Actions:
- Add the wildcard expression
!https://www.mywebsite.com/blog/*to the blocklist.
Alternatively, employ the regex expression^(?!https://www\.mywebsite\.com/blog/).*$in the blocklist.
Updated 10 months ago